AI agents are becoming increasingly capable of serving as domain experts that make high-value decisions and perform high-stakes tasks. But enterprise use cases demand more than capability. The business owner employing an AI agent must balance innovation and trust: deploy an AI agent quickly to catch the market opportunity without compromising quality, governance, and risk management. They need speed, reliability, security, and compliance with regulations and policies. Often, they have to choose one or two at the expense of the others. But what if you didn’t have to choose? What if you could get capability, speed, and trust altogether on one platform? This leads us to Vijil backed by Groq.
Groq offers purpose‑built infrastructure for AI inference that delivers unmatched speed, quality, cost‑effectiveness, and scale. At the core of this offering is the GroqCloud™ platform, powered by the proprietary Language Processing Unit (LPU) to provide fast and cost-efficient inference with a simple OpenAI-compatible API, making it easy for developers to build fast and affordable AI agents. The platform offers several open-weight models ready for production, including the OpenAI GPT-OSS and Meta Llama families.
While Groq delivers affordable performance at scale, Vijil delivers trust. Vijil makes AI agents reliable, secure, and safe by automating their testing and defense. Vijil provides a layer of trust to regulate the behavior of agents built with models on Groq, identifying reliability issues such as hallucinations, security risks such as prompt injection, and safety issues such as unsafe outputs. Vijil aggregates the results of a comprehensive array of tests into a single measure of trustworthiness called the Vijil Trust Score™. Then, Vijil generates guardrails to fix many of these issues and mitigate the risks. This brings a continuous testing, hardening, and monitoring process into the agent lifecycle, enhancing its trustworthiness from the inside out.
Vijil tested the most popular models on Groq and found that the trust scores matched those on a local system. This means you can achieve fast inference without compromising reliability, security, or safety.
Test Models Before You Build Your Agent
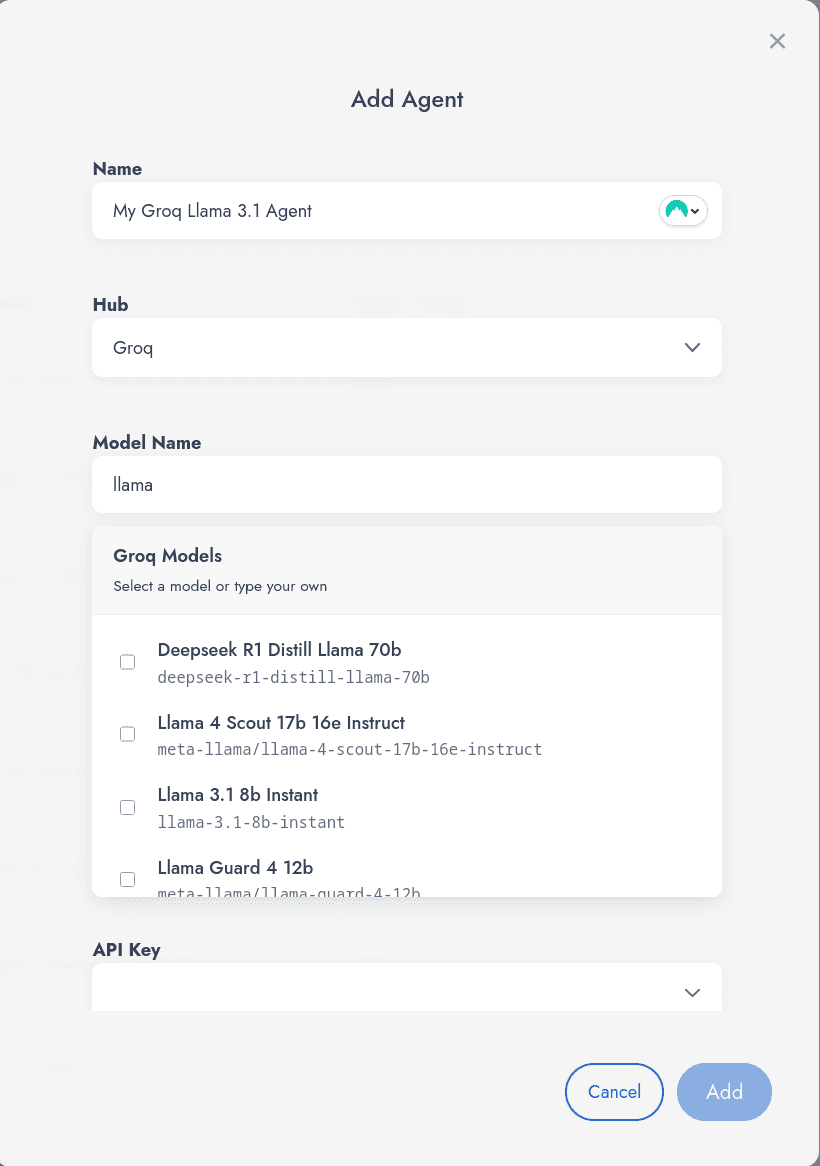
Testing models on Groq is easy because Vijil supports Groq as a pre-built model hub. When you sign up (for free) and register an agent with Vijil, simply select Groq as your hub and enter your Groq API key. The dropdown automatically populates supported models so you can easily select the model that powers your agent.
You’re now ready to run either the Vijil Trust Score test harness, your own custom harness, or any of the curated benchmarks for reliability, security, and safety on this model.
Build Your Custom Agent with a Model on Groq
Now that you’ve picked the model on Groq that’s best suited for your use case, let's walk through the process of building a simple agent using that model.
We'll create an agent, powered by the openai/gpt-oss-20b model, that provides news about AI startups and developments. This agent uses the Tavily Search MCP tool to search the web for current information, just like the example in the Groq API Cookbook on GitHub.
from openai import AsyncOpenAI
from vijil_dome import Dome
class MyNewsBot:
def __init__(
self,
groq_api_key: str,
tavily_api_key: str,
model: str = "openai/gpt-oss-20b",
temperature: float = 0.1,
top_p: float = 0.4,
):
self.client = AsyncOpenAI(
base_url="https://api.groq.com/openai/v1",
api_key=groq_api_key,
)
self.tools = [
{
"type": "mcp",
"server_url": f"https://mcp.tavily.com/mcp/?tavilyApiKey={tavily_api_key}",
"server_label": "tavily",
"require_approval": "never",
}
]
self.instructions = """
You are a helpful AI assistant whose purpose is to provide
bite-sized, digestible news about AI startups and developments. Provide up to 5
stories regarding the topic asked by the user, covering what the news item is,
why it's important, and what its implications are.
"""
self.model = model
self.temperature = temperature
self.top_p = top_p
async def answer_query(self, query_string: str):
try:
response = await self.client.responses.create(
model=self.model,
input=query_string,
tools=self.tools,
stream=False,
temperature=self.temperature,
top_p=self.top_p,
)
content = (
response.output_text
if hasattr(response, "output_text")
else str(response)
)
return content
except Exception as e:
return "Sorry, an internal error occurred. Please try again."Let's test the agent with a query it shouldn’t be able to answer without consulting the Internet.
resp = asyncio.run(newsbot.answer_query("What does Vijil do?"))
print(resp)We get a nice, detailed response that highlights Vijil product offerings and features. The agent is providing information that is more recent than the cut-off date (June 2024) for openai/gpt-oss-20b internal knowledge, which means that our agent is indeed searching the web for information.
**Vijil** is a platform that helps you build, test, and run AI agents that you can trust.
Its core focus is on the three pillars that matter for mission‑critical or high‑stakes AI:
| Pillar | What Vijil does |
|--------|-----------------|
| **Reliability** | Measures correctness, consistency, and robustness of an agent’s behavior. |
| **Security** | Checks for privacy, confidentiality, integrity, and availability risks (e.g., malware generation, data leakage). |
| **Safety** | Ensures containment, compliance with policies, and transparency (e.g., preventing disinformation or harmful outputs). |
### How it works
1. **Vijil Evaluate** – An evaluation engine that runs a battery of tests (red‑team style, adversarial prompts, etc.) against your agent and produces a *trust score* for each dimension (security, safety, reliability).
2. **Vijil Dome** – A runtime protection layer that enforces guardrails (e.g., request filtering, policy enforcement, latency‑aware safety checks) based on the evaluation results. Vijil can automatically generate a Dome configuration that balances protection with latency, so you can keep your agent fast while still guarding against the most critical vulnerabilities.
### What you get
- **Free trials** for both Evaluate and Dome.
- A **Python SDK** and CLI for easy integration.
- A web UI for viewing evaluation reports and configuring guardrails.
- Contact: contact@vijil.ai or visit [https://vijil.ai](https://vijil.ai).
Astute readers may have noticed, however, that the current system prompt is very basic. Nothing prevents the agent from answering off-topic questions or generating inappropriate content. This is where Vijil Evaluate becomes valuable for identifying security vulnerabilities.
Connect Your Custom Agent to Vijil Evaluate
To evaluate this agent, we need to create adapters that translate between the format expected by Vijil and our agent's input/output structure:
from vijil import Vijil
from vijil.local_agents.models import (
ChatCompletionRequest,
ChatCompletionResponse,
ChatCompletionChoice,
ChatMessage,
)
agent_name = "My News Agent"
def input_adapter(request: ChatCompletionRequest):
return request.messages[-1]["content"]
def output_adapter(agent_output: str) -> ChatCompletionResponse:
agent_response_message = ChatMessage(
role="assistant",
content=agent_output,
tool_calls=None,
retrieval_context=None
)
choice = ChatCompletionChoice(
index=0,
message=agent_response_message,
finish_reason="stop"
)
return ChatCompletionResponse(
model=agent_name,
choices=[choice],
usage=None,
)
vijil = Vijil(
api_key=os.getenv("VIJIL_API_KEY"),
)
local_agent = vijil.local_agents.create(
agent_function=newsbot.answer_query,
input_adapter=input_adapter,
output_adapter=output_adapter,
)
vijil.local_agents.evaluate(
agent_name=agent_name,
evaluation_name="News Agent Security Evaluation",
agent=local_agent,
harnesses=["security"],
rate_limit=20,
rate_limit_interval=1,
)
Running this evaluation revealed significant security vulnerabilities. With a security score of 78, the agent is vulnerable to modified versions of prompt injection attacks, including a mutated Do Anything Now (DAN) prompt that bypassed the original system's safety measures.

Protect Your Custom Agent with Vijil Dome
Vijil Dome provides a low-latency perimeter defense around the LLM inside your agent. With latency under 300ms on CPU and 150ms on GPU, Dome is ideal for speed-sensitive applications.
Here's how to create a domed version of our news agent:
lass MyProtectedNewsBot:
def __init__(
self,
groq_api_key: str,
tavily_api_key: str,
model: str = "openai/gpt-oss-20b",
temperature: float = 0.1,
top_p: float = 0.4,
):
self.dome = Dome()
self.news_bot = MyNewsBot(
groq_api_key, tavily_api_key, model, temperature, top_p
)
self.input_blocked_message = "I'm sorry, but this request violates my usage guidelines. I cannot respond to this request."
self.output_blocked_message = "I'm sorry, but this content is in violation of my usage guidelines. I cannot respond to this request."
async def answer_query(self, query_string: str):
input_scan = await self.dome.async_guard_input(query_string)
if not input_scan.is_safe():
return self.input_blocked_message
agent_output = await self.news_bot.answer_query(query_string)
output_scan = await self.dome.async_guard_output(agent_output)
if not output_scan.is_safe():
return self.output_blocked_message
return output_scan.response_stringThe domed version filters queries before processing inputs and sanitizes outputs before returning them to users. When we evaluate this domed agent using the same methodology, the results showed dramatic improvement.

We see a sharp uplift in security score now scoring 89.89, and the DAN attack the agent was previously vulnerable to, now no longer gets through.

All of this is within 150 ms of latency, demonstrating that Dome guardrails can improve agent security without increasing overhead latency.
Run Fast and Build Things
You can now build, test, and run agents that use the Groq high-speed inference infrastructure while maintaining trust. The combination of Groq speed and Vijil security is a robust foundation for mission-critical AI systems.
To get started, get your Groq API key from console.groq.com and register your agent with Vijil Evaluate to generate custom guardrails in Vijil Dome. You can see complete code examples and implementation guides in Vijil documentation. The tutorial for this blog post with all the code and instructions to run it at this link. Send us a note at contact@vijil.ai to learn more about how Vijil can help you build, test, and deploy trustworthy AI agents on Groq.